近日,国际多媒体会议(ACM International Conference on Multimedia, ACM MM 2025)官方公布论文收录结果。ACM MM是多媒体领域全球顶级学术会议之一。此次我集团陈震中教授课题组2023级专业学位博士研究生魏红陈2篇第一作者论文入选ACM MM 2025。
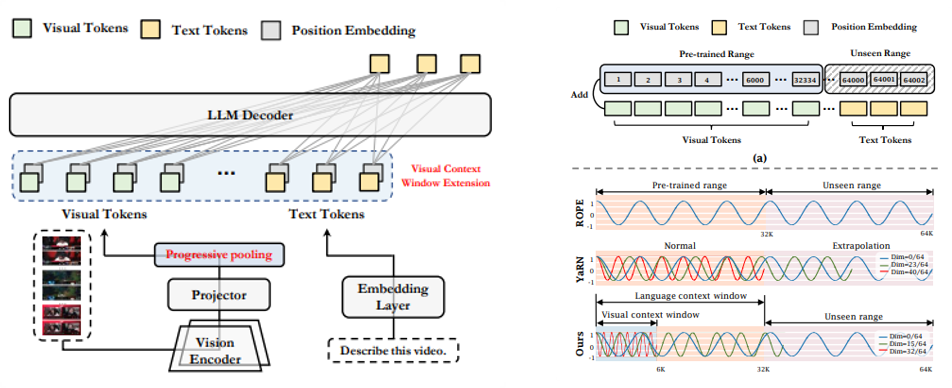
图1 视觉上下文窗口扩展示意图
第一篇论文题为《Visual Context Window Extension: A New Perspective for Long Video Understanding》(作者:魏红陈,陈震中)。该工作从上下文窗口的视角切入,旨在无需长视频数据集重新训练的前提下,实现多模态大语言模型(MLLMs)对长视频任务的有效应用。该工作首先深入分析了预训练MLLMs难以理解长视频内容的原因:视觉与语言模态的差异导致两者标记的上下文窗口不匹配,使得直接扩展视觉标记以对齐语言上下文窗口存在固有困难。基于此发现,提出通过扩展视觉上下文窗口来适配长视频理解任务,从而避免大规模长视频数据的重复训练。为缓解长序列带来的显存压力,该工作进一步设计渐进式池化推理策略——通过动态调整帧嵌入的空间分辨率,在保留关键空间信息的同时显著减少视觉标记数量。在MLVU长视频理解基准上,仅7B参数的模型性能已超越GPT-4o。
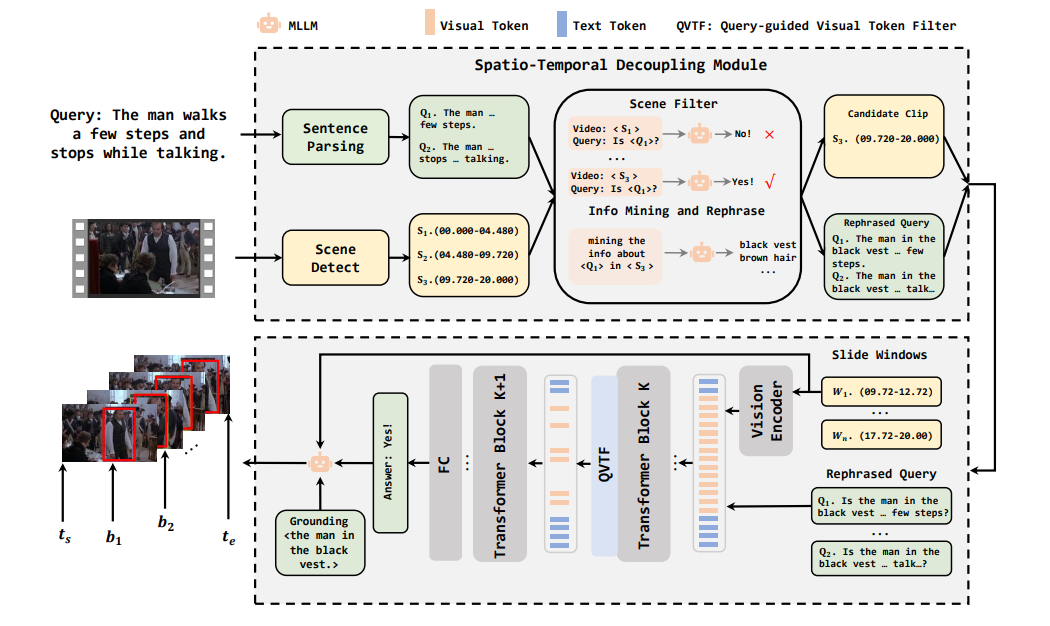
图2 RealVG模型架构示意图
第二篇题为《RealVG: Unleashing MLLMs for Training-Free Spatio-Temporal Video Grounding in the Wild》(作者:魏红陈,陈震中)。时空视频定位(STVG)旨在根据文本查询在视频中定位特定物体或动作的时空区域。由于标注数据在数量和多样性上的局限性,现有方法难以有效泛化到现实场景。为此,该工作提出RealVG——一种无需训练的鲁棒性框架,通过问答机制利用强大的MLLMs实现开放环境下的STVG任务。针对复杂现实视频与查询语句带来的挑战,该工作设计了时空解耦模块和查询引导的视觉令牌过滤器:前者将复杂场景分解为简单子场景与子查询以降低理解难度,提升静态视觉元素的解析精度;后者通过过滤无关视觉令牌来强化目标对象的聚焦能力,从而改善短时动作感知。实验表明,在完全无需STVG训练数据的情况下,RealVG在现实场景中的性能显著超越现有全监督与弱监督方法,展现出卓越的适应性与鲁棒性。
魏红陈为tyc86太阳集团2023级电子信息专业学位博士研究生,本研究获得了腾讯公司校企合作项目支持。